
C4.5算法在数据挖掘中用作决策树分类器,可用于基于特定数据样本(单变量或多变量预示变量)生成决策。
因此,在我们直接深入研究C4.5之前,让我们先讨论一下决策树以及它们如何用作分类器。
决策树
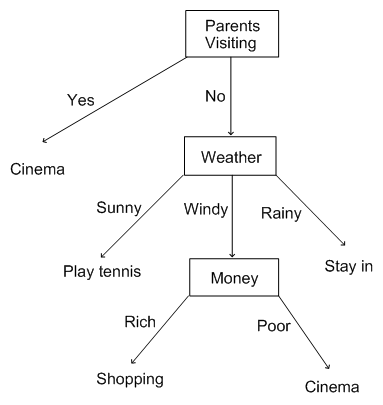
决策树如上图所示。假设您想计划今天的活动,但您面临一些可能影响最终决定的不同条件。
在上图中,我们注意到影响决策的主要因素之一是父母到访(Parent Visiting)。如果确实如此,那么我们会做出快速决定--选择去电影院。如果他们不来怎么办?
这开辟了一系列其他可能。现在,如果天气晴朗(Sunny)或多雨(Rainy),我们要么去打网球(Play tennis),要么待在家里(Stay in)。但是,如果外面多风(Windy),我会检查我拥有多少钱。如果我很有钱(Rich),我会去购物(Shopping),或者去看电影(Cinema)。
树根始终是具有成本函数最小值的变量。在这个例子中,父母访问的概率是50%,无须多虑,一半一半是很容易的决策。但是如果选择天气作为“根”呢?那么将有33.33%的可能性发生某种结果,这可能会增加我们做出错误决定的机会,因为需要考虑更多的测试用例。
如果我们通过信息增益和熵的概念,那将更容易理解。
信息增益
如果您已经获得了加班信息,这有助于您准确预测某些事情是否会发生,那么您预测的事情信息就不是新信息。但是,如果情况有变并且出现了意想不到的结果,那么它就算是有用和必要的信息。
类似的是信息增益的概念。
您对某个主题了解得越多,您就越不了解它的新信息。更简洁:如果你知道一个事件是非常可能的,那么当事件发生时就不足为奇了,也就是说,它提供的实际情况信息很少。
从上面的陈述中我们可以表明,获得的信息量与事件发生的概率成反比。我们还可以说随着熵增加,信息增益减少。这是因为熵指的是事件的概率。
假设我们正在看抛硬币。猜中双面平整的硬币任何一面的概率为50%。如果硬币是不平整的,那么获得某面(头或尾部)的概率是1.00,然后我们说熵是最小的,因为目前没有任何类型的试验可以预测我们硬币投掷的结果。
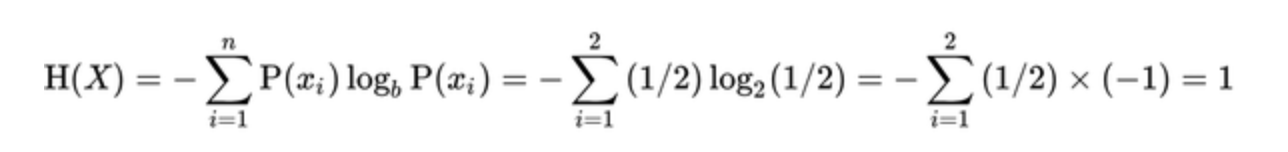
屏幕快照2018-09-25上午11.56.56.png
在下面的绘制图中,我们注意到由于特定事件的最大不确定性而获得的最大信息量是当每个事件的概率相等时。这里,p=q=0.5
E=系统事件的熵
p=头部作为结果的概率
q=尾部作为结果的概率
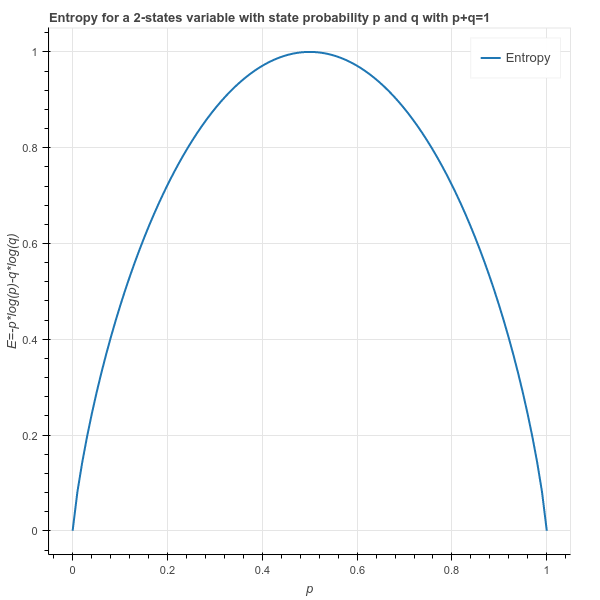
在决策树的情况下,必须使节点对齐,所以熵随着向下分裂而减小。这基本上意味着更多的分裂是适当的,做出明确的决定变得更容易。
因此,我们针对每种分裂可能性检查每个节点。信息增益比是观测值与观测总数之比(m/N=p)和(n/N=q),其中m+n=N且p+q=1。在分裂之后,如果下一个节点的熵小于分裂之前的熵,并且如果该值与用于分裂的所有可能测试用例相比最小,则该节点被分裂成其最纯的成分。
在我们的例子中,我们发现与其他选项相比,父母访问以更大的比例减少熵。因此,我们选择这个选项。
修剪
我们原始示例中的决策树非常简单,但是当数据集很大并且需要考虑更多变量时,情况并非如此。这是需要修剪的地方。修剪是指,在我们的决策树中删除那些我们认为对我们的决策过程没有显着贡献的分支。
让我们假设我们的示例数据有一个名为“车辆”的变量,当它具有值“富裕”(Rich)时,它与条件“钱”(Money)相关或是其衍生。现在,如果车辆可用,我们将通过汽车购物(shopping),但如果没有,我们可以通过任何其他交通方式购物。但最终我们去购物。
这意味着“车辆”变量没有多大意义,可以在构造决策树时排除。
修剪的概念使我们能够避免过度拟合回归或分类模型,以便对于少量数据样本,在生成模型时摒除测量误差。
虚拟代码
C4.5优于其他决策树系统的优势:
1.该算法固有地采用单通道修剪过程来减轻过度拟合。
2.它可以与离散数据和连续数据一起使用
3.C4.5可以很好地处理不完整数据的问题
4.也许C4.5并不是最好的算法,但在某些情况下确实有用。